
Pandas를 이용한 데이터 분석(1)
Pandas란 무엇인가?
pandas is a fast, powerful, flexible and easy to use open source data analysis and manipulation tool, built on top of the Python programming language.
Pandas 홈페이지에 나와있는 설명문이다. 빠르고 유연하고 기능이 많으며, 사용하기 쉬운 파이썬 기반의 오픈소스 데이터 분석 및 조작 도구라고 한다. 많은 파이썬 유저들이 정형 데이터를 분석할 때 애용하고 있는 라이브러리이다. 좀 더 설명하면 파이썬에서 엑셀과 같이 데이터를 표형식으로 읽고, 바꾸고, 분석하는 도구라고 할 수 있겠다. 엑셀만큼 쉽지는 않겠지만 한번 익숙해진다면 많은 양의 데이터를 엑셀보다 훨씬 빠르게 처리할 수 있을 것이다.
Pandas 설치
Anaconda를 설치했다면 base에 이미 설치되어 있겠지만 설치가 안 된 사람들은 다음과 같은 명령어로 설치하도록 하자.
conda install pandas # Conda를 이용해 설치하는 방법
pip install pandas # Pypl을 이용해 설치하는 방법
샘플 데이터셋을 이용한 Pandas 기능 살펴보기
데이터 가시화 라이브러리인 Seaborn에서는 몇몇 샘플 데이터셋을 제공한다. 이 중 하나인 펭귄 데이터셋을 읽어서 Pandas의 기능을 살펴보도록 하겠다.
먼저 다음과 같은 라이브러리를 사용할 것이다.
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
샘플 펭귄 데이터셋 읽기 & DataFrame.head()
Pandas에서 데이터셋을 처리하기 위해 DataFrame이란 데이터 형식을 사용한다.- DataFrame 변수는 주로 약어로 df라는 이름으로 선언된다.
sns.load_dataset('penguins')로 펭귄 데이터셋을 읽어준 후, DataFrame.head()로 데이터셋의 첫 몇 행을 확인해보자.
df = sns.load_dataset('penguins') ## 샘플 데이터셋을 읽어서 df로 선언
df.head(10) ## 첫 10개 행 확인
| species | island | bill_length_mm | bill_depth_mm | flipper_length_mm | body_mass_g | sex | |
|---|---|---|---|---|---|---|---|
| 0 | Adelie | Torgersen | 39.1 | 18.7 | 181.0 | 3750.0 | MALE |
| 1 | Adelie | Torgersen | 39.5 | 17.4 | 186.0 | 3800.0 | FEMALE |
| 2 | Adelie | Torgersen | 40.3 | 18.0 | 195.0 | 3250.0 | FEMALE |
| 3 | Adelie | Torgersen | NaN | NaN | NaN | NaN | NaN |
| 4 | Adelie | Torgersen | 36.7 | 19.3 | 193.0 | 3450.0 | FEMALE |
| 5 | Adelie | Torgersen | 39.3 | 20.6 | 190.0 | 3650.0 | MALE |
| 6 | Adelie | Torgersen | 38.9 | 17.8 | 181.0 | 3625.0 | FEMALE |
| 7 | Adelie | Torgersen | 39.2 | 19.6 | 195.0 | 4675.0 | MALE |
| 8 | Adelie | Torgersen | 34.1 | 18.1 | 193.0 | 3475.0 | NaN |
| 9 | Adelie | Torgersen | 42.0 | 20.2 | 190.0 | 4250.0 | NaN |
DataFrame.tail()
반대로 DataFrame.tail()을 사용하여 마지막 몇 행을 확인하는 것도 가능하다.
안에 변수를 넣지 않는다면 기본값으로 5개의 행을 확인한다.
df.tail() ## 마지막 5개 행 확인
| species | island | bill_length_mm | bill_depth_mm | flipper_length_mm | body_mass_g | sex | |
|---|---|---|---|---|---|---|---|
| 339 | Gentoo | Biscoe | NaN | NaN | NaN | NaN | NaN |
| 340 | Gentoo | Biscoe | 46.8 | 14.3 | 215.0 | 4850.0 | FEMALE |
| 341 | Gentoo | Biscoe | 50.4 | 15.7 | 222.0 | 5750.0 | MALE |
| 342 | Gentoo | Biscoe | 45.2 | 14.8 | 212.0 | 5200.0 | FEMALE |
| 343 | Gentoo | Biscoe | 49.9 | 16.1 | 213.0 | 5400.0 | MALE |
DataFrame.info()
DataFrame.info()를 사용하면 데이터의 각 열 별로 데이터 형식이나 값의 개수 등을 확인할 수 있다.
df.info()
## cf. object : int, string, list 등 모든 종류의 데이터
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 344 entries, 0 to 343
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 species 344 non-null object
1 island 344 non-null object
2 bill_length_mm 342 non-null float64
3 bill_depth_mm 342 non-null float64
4 flipper_length_mm 342 non-null float64
5 body_mass_g 342 non-null float64
6 sex 333 non-null object
dtypes: float64(4), object(3)
memory usage: 18.9+ KB
DataFrame.describe()
데이터의 각 열 별 평균, 표준편차, 최솟값, 중앙값, 최댓값 등을 한번에 확인할 수 있다.
df.describe() ## 데이터의 각 열 별 평균, 표준편차, 최솟값, 중앙값, 최댓값
| bill_length_mm | bill_depth_mm | flipper_length_mm | body_mass_g | |
|---|---|---|---|---|
| count | 342.000000 | 342.000000 | 342.000000 | 342.000000 |
| mean | 43.921930 | 17.151170 | 200.915205 | 4201.754386 |
| std | 5.459584 | 1.974793 | 14.061714 | 801.954536 |
| min | 32.100000 | 13.100000 | 172.000000 | 2700.000000 |
| 25% | 39.225000 | 15.600000 | 190.000000 | 3550.000000 |
| 50% | 44.450000 | 17.300000 | 197.000000 | 4050.000000 |
| 75% | 48.500000 | 18.700000 | 213.000000 | 4750.000000 |
| max | 59.600000 | 21.500000 | 231.000000 | 6300.000000 |
여기에 변수로 include='all'을 추가하게 된다면 str같은 object 데이터에 대해서도 최빈값 등을 알려준다.
df.describe(include='all')
| species | island | bill_length_mm | bill_depth_mm | flipper_length_mm | body_mass_g | sex | |
|---|---|---|---|---|---|---|---|
| count | 344 | 344 | 342.000000 | 342.000000 | 342.000000 | 342.000000 | 333 |
| unique | 3 | 3 | NaN | NaN | NaN | NaN | 2 |
| top | Adelie | Biscoe | NaN | NaN | NaN | NaN | MALE |
| freq | 152 | 168 | NaN | NaN | NaN | NaN | 168 |
| mean | NaN | NaN | 43.921930 | 17.151170 | 200.915205 | 4201.754386 | NaN |
| std | NaN | NaN | 5.459584 | 1.974793 | 14.061714 | 801.954536 | NaN |
| min | NaN | NaN | 32.100000 | 13.100000 | 172.000000 | 2700.000000 | NaN |
| 25% | NaN | NaN | 39.225000 | 15.600000 | 190.000000 | 3550.000000 | NaN |
| 50% | NaN | NaN | 44.450000 | 17.300000 | 197.000000 | 4050.000000 | NaN |
| 75% | NaN | NaN | 48.500000 | 18.700000 | 213.000000 | 4750.000000 | NaN |
| max | NaN | NaN | 59.600000 | 21.500000 | 231.000000 | 6300.000000 | NaN |
평균, 중앙값, 최댓값, 최솟값
print('평균')
print(df.mean())
print('\n중앙값')
print(df.median())
print('\n최댓값')
print(df.max())
print('\n최솟값')
print(df.min())
평균
bill_length_mm 43.921930
bill_depth_mm 17.151170
flipper_length_mm 200.915205
body_mass_g 4201.754386
dtype: float64
중앙값
bill_length_mm 44.45
bill_depth_mm 17.30
flipper_length_mm 197.00
body_mass_g 4050.00
dtype: float64
최댓값
species Gentoo
island Torgersen
bill_length_mm 59.6
bill_depth_mm 21.5
flipper_length_mm 231
body_mass_g 6300
dtype: object
최솟값
species Adelie
island Biscoe
bill_length_mm 32.1
bill_depth_mm 13.1
flipper_length_mm 172
body_mass_g 2700
dtype: object
데이터 가시화
Seaborn을 이용하여 간단하게 데이터를 가시화해보자
## 여러 그래프 그리기 1 : plt.subplots
fig, ax = plt.subplots(nrows=1, ncols=3, figsize=(15,5))
sns.countplot(x='island', data=df, ax=ax[0])
sns.countplot(x='species', data=df, ax=ax[1])
sns.countplot(x='sex', data=df, ax=ax[2])
plt.show()
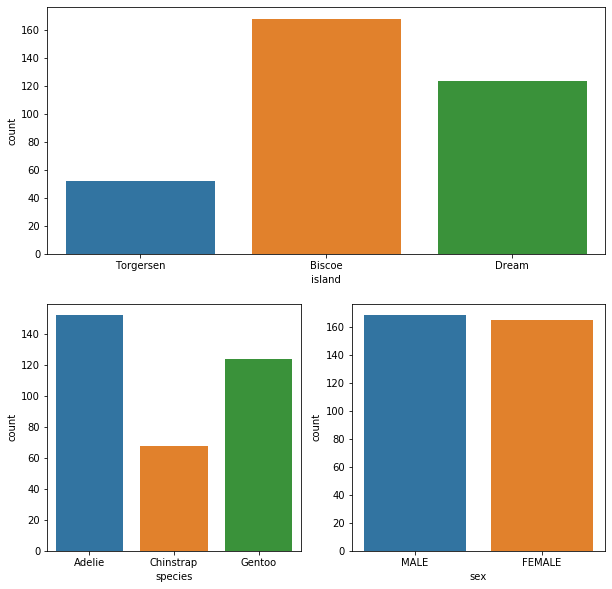
## 여러 그래프 그리기 2 : plt.subplot
fig = plt.figure(figsize=(10,10))
ax = fig.add_subplot(2, 1, 1) ## nrows, ncols, index
sns.countplot(x='island', data=df, ax=ax)
ax = fig.add_subplot(2, 2, 3) ## nrows, ncols, index
sns.countplot(x='species', data=df, ax=ax)
ax = fig.add_subplot(2, 2, 4) ## nrows, ncols, index
sns.countplot(x='sex', data=df, ax=ax)
plt.show()
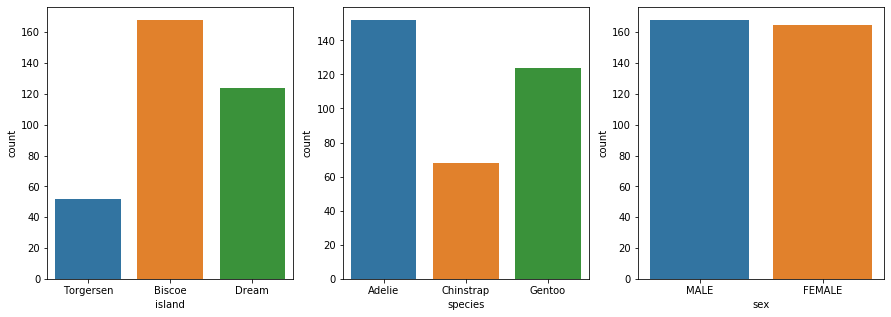
sns.countplot(x='island',hue='species',data=df)
plt.show()
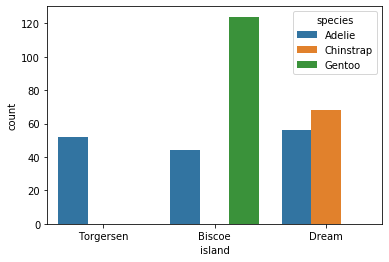
데이터 슬라이싱
데이터셋이라면 당연 특정 열이나 행만 뽑아내거나 특정 조건 하에 데이터를 필터링할 수 있어야 한다.
우선 데이터의 열 데이터는 column이라 불리며, DataFrame.columns로 확인할 수 있다. 펭귄 데이터셋의 경우 종, 부리의 길이, 부리의 깊이, 물갈퀴의 길이, 몸무게, 성별의 열을 가지고 있다.
행 데이터는 index로써 표현된다. 펭귄 데이터셋의 경우 index는 0부터 시작하는 int값이지만, 굳이 int값이 아니어도 되며 웬만한 데이터 형식이면 다 가능하다.
print('COLUMN', df.columns)
print('INDEX',df.index)
COLUMN Index(['species', 'island', 'bill_length_mm', 'bill_depth_mm',
'flipper_length_mm', 'body_mass_g', 'sex'],
dtype='object')
INDEX RangeIndex(start=0, stop=344, step=1)
행 추출
기본적으로 행을 추출하기 위해서는 DataFrame.loc을 사용한다. Dictionary에 key를 넣듯 대괄호 안에 index의 이름을 넣어주면 그 index에 해당하는 데이터가 출력된다.
여기에서 한 가지 중요한 점이, 대괄호 안에 들어갈 것이 index의 값(혹은 이름)이라는 것이다. 위에서도 언급햇듯이 index가 굳이 int값이 아니어도 되며, str일 수도 있다.
만약에 DataFrame df에서 index 값이 ‘asdf’인 행을 출력하고 싶다면 df['asdf']라고 적으면 된다.
이외에도 index의 값이 아니라 index의 순서로 행을 출력하는 것이 가능하다. 이는 DataFrame.iloc으로 할 수 있다. iloc을 사용하게 되면 list에서 원하는 값을 출력하듯 값이 위치한 순서를 입력하면 된다.
예를 들면, 펭귄 데이터셋에서 df.iloc[-5]는 데이터셋에서 마지막에서 5번째 행의 데이터를 출력하지만 index의 값이 -5인 행은 없기 때문에 df.loc[-5]는 오류가 난다.
대괄호 안에 list를 넣어서 복수의 행을 출력할 수도 있다. df.loc[[3, 5, 7, 10]]처럼 입력한다면 index값이 3, 5, 7, 10인 행을 출력한다.
이외에도 df.loc[339:350:2]나 df.iloc[339:350:2]처럼 slicing을 할 수 있지만 이 경우는 index값이 int형식이라 가능한 것이고 일반적으로는 iloc만 slicing할 수 있다.
loc이나 iloc에 하나의 행만 출력하도록 값을 넣는다면 복수의 행을 출력할 때와는 데이터가 다른 식으로 나온다. 이를 Series라 하며, 하나의 행 또는 열을 다루기 위한 데이터 형식이다. 만약 하나의 행만을 출력하되 형식이 Series가 아니라 DataFrame으로 나오도록 하고 싶다면
df.loc[[5]]처럼 list로 만들어 넣어주면 된다.
## 특정 행 추출 : df.loc, df.iloc
print(df.loc[339]) ## index의 이름이 339인 데이터 출력
print(df.iloc[-5]) ## 마지막에서 5번째 index의 데이터 출력
## 복수의 행 추출 : list 사용
indices = [5,10,15,20,25]
df.loc[indices]
## 이 때, loc[] 안에 int를 넣으면 Series가 출력, list를 넣으면 DataFrame이 출력됨
## Series는 데이터의 한 열 또는 행을 표현하기 위한 데이터 형식
species Gentoo
island Biscoe
bill_length_mm NaN
bill_depth_mm NaN
flipper_length_mm NaN
body_mass_g NaN
sex NaN
Name: 339, dtype: object
species Gentoo
island Biscoe
bill_length_mm NaN
bill_depth_mm NaN
flipper_length_mm NaN
body_mass_g NaN
sex NaN
Name: 339, dtype: object
| species | island | bill_length_mm | bill_depth_mm | flipper_length_mm | body_mass_g | sex | |
|---|---|---|---|---|---|---|---|
| 5 | Adelie | Torgersen | 39.3 | 20.6 | 190.0 | 3650.0 | MALE |
| 10 | Adelie | Torgersen | 37.8 | 17.1 | 186.0 | 3300.0 | NaN |
| 15 | Adelie | Torgersen | 36.6 | 17.8 | 185.0 | 3700.0 | FEMALE |
| 20 | Adelie | Biscoe | 37.8 | 18.3 | 174.0 | 3400.0 | FEMALE |
| 25 | Adelie | Biscoe | 35.3 | 18.9 | 187.0 | 3800.0 | FEMALE |
열 추출
열을 추출하는 데에는 다음과 같이 4가지 방법이 있다.
## 특정 열 추출 : 4가지 방법
print(df.species)
print(df['species'])
print(df.loc[:,'species']) ## 모든 index에 대해 species column 출력
print(df.iloc[:, 0]) ## 0번째 column인 species 출력
0 Adelie
1 Adelie
2 Adelie
3 Adelie
4 Adelie
...
339 Gentoo
340 Gentoo
341 Gentoo
342 Gentoo
343 Gentoo
Name: species, Length: 344, dtype: object
0 Adelie
1 Adelie
2 Adelie
3 Adelie
4 Adelie
...
339 Gentoo
340 Gentoo
341 Gentoo
342 Gentoo
343 Gentoo
Name: species, Length: 344, dtype: object
0 Adelie
1 Adelie
2 Adelie
3 Adelie
4 Adelie
...
339 Gentoo
340 Gentoo
341 Gentoo
342 Gentoo
343 Gentoo
Name: species, Length: 344, dtype: object
0 Adelie
1 Adelie
2 Adelie
3 Adelie
4 Adelie
...
339 Gentoo
340 Gentoo
341 Gentoo
342 Gentoo
343 Gentoo
Name: species, Length: 344, dtype: object
## 복수의 열 추출 : list 사용
cols = ['species', 'island', 'bill_length_mm']
print(df.loc[:,cols])
print(df[cols])
cols = [0, 1, 2]
print(df.iloc[:,cols])
species island bill_length_mm
0 Adelie Torgersen 39.1
1 Adelie Torgersen 39.5
2 Adelie Torgersen 40.3
3 Adelie Torgersen NaN
4 Adelie Torgersen 36.7
.. ... ... ...
339 Gentoo Biscoe NaN
340 Gentoo Biscoe 46.8
341 Gentoo Biscoe 50.4
342 Gentoo Biscoe 45.2
343 Gentoo Biscoe 49.9
[344 rows x 3 columns]
species island bill_length_mm
0 Adelie Torgersen 39.1
1 Adelie Torgersen 39.5
2 Adelie Torgersen 40.3
3 Adelie Torgersen NaN
4 Adelie Torgersen 36.7
.. ... ... ...
339 Gentoo Biscoe NaN
340 Gentoo Biscoe 46.8
341 Gentoo Biscoe 50.4
342 Gentoo Biscoe 45.2
343 Gentoo Biscoe 49.9
[344 rows x 3 columns]
species island bill_length_mm
0 Adelie Torgersen 39.1
1 Adelie Torgersen 39.5
2 Adelie Torgersen 40.3
3 Adelie Torgersen NaN
4 Adelie Torgersen 36.7
.. ... ... ...
339 Gentoo Biscoe NaN
340 Gentoo Biscoe 46.8
341 Gentoo Biscoe 50.4
342 Gentoo Biscoe 45.2
343 Gentoo Biscoe 49.9
[344 rows x 3 columns]
위에서 살펴본 열과 행의 추출 방법으로 동시에 추출하는 것이 가능하다. 이를 위해서는 loc이나 iloc을 사용할 수 있다.
### 열 및 행 추출
indices = [5, 10]
cols = ['species', 'bill_length_mm']
df.loc[indices, cols]
| species | bill_length_mm | |
|---|---|---|
| 5 | Adelie | 39.3 |
| 10 | Adelie | 37.8 |
데이터 필터링
이 데이터셋에는 3가지 종의 펭귄이 있다. 이 중 아델리펭귄의 데이터만 뽑고싶다면 어떻게 할 수 있을까? == 기호를 통해서 펭귄의 종이 아델리인 index를 뽑는 것이 가능하다.
## 데이터 필터링
print(df['species']=='Adelie') ## species가 Adelie인 index는 True로, 나머지는 False로
0 True
1 True
2 True
3 True
4 True
...
339 False
340 False
341 False
342 False
343 False
Name: species, Length: 344, dtype: bool
이렇게 해서 뽑은 index로 DataFrame을 필터링하면 아델리 펭귄만 뽑는 것이 가능하다.
df.loc[df['species']=='Adelie'] ## species가 Adelie인 index만 출력
| species | island | bill_length_mm | bill_depth_mm | flipper_length_mm | body_mass_g | sex | |
|---|---|---|---|---|---|---|---|
| 0 | Adelie | Torgersen | 39.1 | 18.7 | 181.0 | 3750.0 | MALE |
| 1 | Adelie | Torgersen | 39.5 | 17.4 | 186.0 | 3800.0 | FEMALE |
| 2 | Adelie | Torgersen | 40.3 | 18.0 | 195.0 | 3250.0 | FEMALE |
| 3 | Adelie | Torgersen | NaN | NaN | NaN | NaN | NaN |
| 4 | Adelie | Torgersen | 36.7 | 19.3 | 193.0 | 3450.0 | FEMALE |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 147 | Adelie | Dream | 36.6 | 18.4 | 184.0 | 3475.0 | FEMALE |
| 148 | Adelie | Dream | 36.0 | 17.8 | 195.0 | 3450.0 | FEMALE |
| 149 | Adelie | Dream | 37.8 | 18.1 | 193.0 | 3750.0 | MALE |
| 150 | Adelie | Dream | 36.0 | 17.1 | 187.0 | 3700.0 | FEMALE |
| 151 | Adelie | Dream | 41.5 | 18.5 | 201.0 | 4000.0 | MALE |
152 rows × 7 columns
마찬가지로 아델리 펭귄의 부리에 관한 데이터만 보고 싶다면 다음과 같이 적을 수 있다.
## species가 Adelie인 데이터의 bill_length_mm와 bill_depth_mm 값만 출력
df.loc[df['species']=='Adelie', ['bill_length_mm', 'bill_depth_mm']]
| bill_length_mm | bill_depth_mm | |
|---|---|---|
| 0 | 39.1 | 18.7 |
| 1 | 39.5 | 17.4 |
| 2 | 40.3 | 18.0 |
| 3 | NaN | NaN |
| 4 | 36.7 | 19.3 |
| ... | ... | ... |
| 147 | 36.6 | 18.4 |
| 148 | 36.0 | 17.8 |
| 149 | 37.8 | 18.1 |
| 150 | 36.0 | 17.1 |
| 151 | 41.5 | 18.5 |
152 rows × 2 columns
결측값 매꾸기
# 각 값이 NaN인지 확인
df.isna()
| species | island | bill_length_mm | bill_depth_mm | flipper_length_mm | body_mass_g | sex | |
|---|---|---|---|---|---|---|---|
| 0 | False | False | False | False | False | False | False |
| 1 | False | False | False | False | False | False | False |
| 2 | False | False | False | False | False | False | False |
| 3 | False | False | True | True | True | True | True |
| 4 | False | False | False | False | False | False | False |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 339 | False | False | True | True | True | True | True |
| 340 | False | False | False | False | False | False | False |
| 341 | False | False | False | False | False | False | False |
| 342 | False | False | False | False | False | False | False |
| 343 | False | False | False | False | False | False | False |
344 rows × 7 columns
# 각 열 별로 NaN값이 존재하는지 확인
print(df.isna().any())
species False
island False
bill_length_mm True
bill_depth_mm True
flipper_length_mm True
body_mass_g True
sex True
dtype: bool
# 각 행 별로 NaN값이 존재하는지 확인
df.isna().any(axis=1)
0 False
1 False
2 False
3 True
4 False
...
339 True
340 False
341 False
342 False
343 False
Length: 344, dtype: bool
## NaN값이 존재하는 행만 출력
df.loc[df.isna().any(axis=1)]
| species | island | bill_length_mm | bill_depth_mm | flipper_length_mm | body_mass_g | sex | |
|---|---|---|---|---|---|---|---|
| 3 | Adelie | Torgersen | NaN | NaN | NaN | NaN | NaN |
| 8 | Adelie | Torgersen | 34.1 | 18.1 | 193.0 | 3475.0 | NaN |
| 9 | Adelie | Torgersen | 42.0 | 20.2 | 190.0 | 4250.0 | NaN |
| 10 | Adelie | Torgersen | 37.8 | 17.1 | 186.0 | 3300.0 | NaN |
| 11 | Adelie | Torgersen | 37.8 | 17.3 | 180.0 | 3700.0 | NaN |
| 47 | Adelie | Dream | 37.5 | 18.9 | 179.0 | 2975.0 | NaN |
| 246 | Gentoo | Biscoe | 44.5 | 14.3 | 216.0 | 4100.0 | NaN |
| 286 | Gentoo | Biscoe | 46.2 | 14.4 | 214.0 | 4650.0 | NaN |
| 324 | Gentoo | Biscoe | 47.3 | 13.8 | 216.0 | 4725.0 | NaN |
| 336 | Gentoo | Biscoe | 44.5 | 15.7 | 217.0 | 4875.0 | NaN |
| 339 | Gentoo | Biscoe | NaN | NaN | NaN | NaN | NaN |
## NaN값 채우기 : fillna
df2 = df.fillna(df.mean())
df2
| species | island | bill_length_mm | bill_depth_mm | flipper_length_mm | body_mass_g | sex | |
|---|---|---|---|---|---|---|---|
| 0 | Adelie | Torgersen | 39.10000 | 18.70000 | 181.000000 | 3750.000000 | MALE |
| 1 | Adelie | Torgersen | 39.50000 | 17.40000 | 186.000000 | 3800.000000 | FEMALE |
| 2 | Adelie | Torgersen | 40.30000 | 18.00000 | 195.000000 | 3250.000000 | FEMALE |
| 3 | Adelie | Torgersen | 43.92193 | 17.15117 | 200.915205 | 4201.754386 | NaN |
| 4 | Adelie | Torgersen | 36.70000 | 19.30000 | 193.000000 | 3450.000000 | FEMALE |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 339 | Gentoo | Biscoe | 43.92193 | 17.15117 | 200.915205 | 4201.754386 | NaN |
| 340 | Gentoo | Biscoe | 46.80000 | 14.30000 | 215.000000 | 4850.000000 | FEMALE |
| 341 | Gentoo | Biscoe | 50.40000 | 15.70000 | 222.000000 | 5750.000000 | MALE |
| 342 | Gentoo | Biscoe | 45.20000 | 14.80000 | 212.000000 | 5200.000000 | FEMALE |
| 343 | Gentoo | Biscoe | 49.90000 | 16.10000 | 213.000000 | 5400.000000 | MALE |
344 rows × 7 columns